
GCN Assembler for AMD GPUs
An assembler/compiler for AMD's Graphics Core Next assembly language
by Ryan Scott White — Feb 17, 2015 (updated April 2016)
71,916 views on CodeProject(2015-2023)Contents
Introduction
This GCN GPU assembly compiler converts human-readable assembly into binary machine code for AMD GCN GPUs. Assembly is a readable abstraction of machine code; most assembly statements map directly to single hardware instructions. Performance-critical software or code that needs special hardware features often uses assembly. A typical example is Bitcoin mining: the workload is compute-bound and benefits from small gains, and assembly can access instructions and options that are otherwise unavailable. Assembly also lets you combine instructions creatively. The trade-offs are maintainability and portability; see Disadvantages section below.
The project includes three Visual Studio projects that wrap one another:
Asm4GCN Assembler — converts assembly statement blocks to binary; manages variables, labels, and registers; reports warnings and errors.
OpenCLwithGCN — injects assembled binaries into dummy OpenCL kernels and runs the program.
Asm4GCNGUI — a Windows editor with syntax highlighting and code completion, useful for experimenting and for demonstrating OpenCLwithGCN.
Background
On NVIDIA, CUDA supports inline PTX via asm, which provides a PTX-level "almost assembly" experience. In OpenCL for AMD, there is no straightforward way to inline GCN assembly.
The ideal would be an asm function in OpenCL. Some users have partially made this work, but without variable in/out passing it is not useful, and register clobbering is a risk.
I pursued inline assembly by generating a dummy kernel of the right size and capturing used registers. Reliability was poor, so I pivoted: a cl::program can mix OpenCL __kernel and GCN __asm4GCN kernels. Inline assembly infrastructure remains half-built; capturing registers for dynamic dummy kernels is still the blocker.
A related Windows app is HetPas by Realhet. It produces ELF images loadable into OpenCL and runs GCN assembly kernels with Pascal-like host code. It works well; I struggled with Pascal, which motivated this project.
Asm4GCN Assembler Sub-Project
The solution has three projects: Asm4GCN (assembler), OpenCLwithGCN, and Asm4GcnGUI. The Asm4GCN core converts assembly to raw binary.
Example: s_mov_b32 v1, s0 → 7E020200
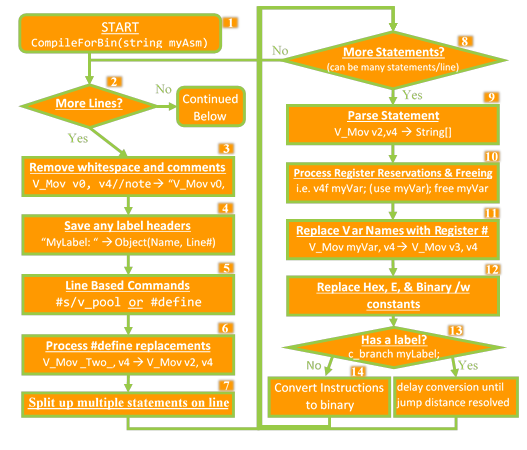
Beyond opcode encoding, the assembler handles labels, jumps, variables, and register management. The following flow abstracts the core passes (simplified):
Assembly Flow - Pass 1
1. Input a block of GCN assembly.
2. Iterate line by line.
3. Strip whitespace and comments.
4. Record label headers like myLabel:.
5. Process #s_pool, #v_pool, and #define.
6. Apply #define replacements.
7. Split multiple statements by ;.
8. For each statement on the line:
9. Tokenize: V_Mov v2, v4 → {"V_Mov","v2","v4"}.
10. Handle variable allocate/free.
11. Substitute variable names with assigned registers.
12. Parse literals: hex, bin, octal, scientific.
13. If a label is referenced, defer final encoding.
14. Encode instruction to binary if fully resolved.
15. Append to the instruction list.
Assembly Flow - Pass 2 (Resolve unknown instruction sizes)
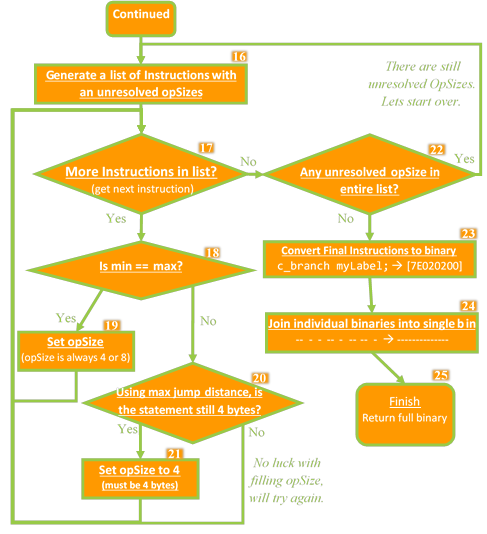
16. Collect instructions with unresolved size.
17. Iterate them.
18. If min/max jump distances agree, size is fixed.
19. Set byte size accordingly.
20. If even the farthest jump fits 4 bytes, fix to 4.
21. Mark as 4-byte op.
22. Repeat until all sizes are resolved.
23. Encode remaining label-based instructions.
24. Concatenate 4- and 8-byte ops into one byte array.
25. Return the binary and metadata (register usage, etc.).
Labels
Branches may encode to 32 or 64 bits depending on jump distance. Distances depend on sizes of intervening instructions, but those sizes depend on whether intervening branches are 32 or 64 bits. To break the cycle, compute lower and upper bounds: assume unresolved ops are 32-bit for a shortest path, and 64-bit for a longest path. Whenever both bounds agree on 32 or 64 bits, lock that size. Iterate over unresolved branches until all sizes stabilize, then substitute concrete label distances.
A simpler but less efficient fallback is always using the 64-bit form when unsure.
Label features:
Labels can stand anywhere constants can. s_mov s2, MyLabel moves the byte distance to MyLabel into s2. Beware instructions that cannot take two constants (e.g., s_sub s4, MyLabelA, MyLabelB).
Duplicate label names are allowed; the nearest matching label is used. This eases copy-paste, but a warning is emitted to catch unintended jumps.
Variables
Assembly beyond ~20 lines quickly becomes hard to track. Variables solve two problems: naming intent and safe register reuse.
Example:
v_mov_b32 myVar1, 10;
v_mov_b32 myVar2, 20;
v_add_i32 mySum, myVar1, myVar2
free myVar1, myVar2
The variable system has three parts: declaration, use, and freeing.
Declaring a Variable
Use short 3-character types: first char is space (S=scalar, V=vector), middle is size in bytes, last is intended data kind (F/I/U/B). On declaration the allocator reserves the first free register(s) from the allowed pool.

Examples:
v8u myUnsignedLongVector;
s8f myDoubleScalar1, myDoubleScalar2; // multiple per line
s4u myAddrForcedToS10 s10; // force s10 (e.g., incoming params)
v8f myDoubleForcedTo2 v[2:3]; // force v[2:3] or just v2
| First character: | Description |
|---|---|
s or v |
selects the register file. |
Size (middle, updated):
Byte size controls how many consecutive registers are reserved and their alignment. Sizes 1/2/4 still occupy one dword register; 8 uses two consecutive registers, aligned by 2; 16 uses four, aligned by 4; 32 uses eight, aligned by 4.
| Size | Regs used | Alignment |
|---|---|---|
| 1 byte | 1 | any |
| 2 byte | 1 | any |
| 4 byte | 1 | any |
| 8 byte | 2 | begin on reg divisible by 2 |
| 16 byte | 4 | begin on reg divisible by 4 |
| 32 byte | 8 | begin on reg divisible by 4 |
Data kind (last):
F float, I signed int, U unsigned, B bits (catch-all). Currently informational; future checks could warn on mismatched ops.
Forcing Register Numbers
Two ways to pin a declaration to specific registers:
1. Fixed register: v4u myLaneID v0
2. Copy from an earlier variable (optionally with an index): s4u myNewVar myPast16SizedVar[3]
Use fixed registers early in kernels to avoid allocator conflicts. Reusing a past variable's register lets you "rename" without a move, reduces peak registers, and avoids extra instructions.
Inline Variable Declarations
You can declare inline at the point of first use:
Without inline:
v_mov_b32 vLocalSize, localSize
v_mul_i32_i24 vLocalSize, groupId, vLocalSize
v4u localSizeIdx
v_add_i32 localSizeIdx, vcc, laneId, vLocalSize
v4u vGlobalID
v_add_i32 vGlobalID, vcc, baseGlobalId, localSizeIdx
v4u vGlobalOffset
v_lshlrev_b32 vGlobalOffset, 2, vGlobalID
With inline:
v_mul_i32_i24 vLocalSize, groupId, vLocalSize
v_add_i32 v4u localSizeIdx, vcc, laneId, vLocalSize
v_add_i32 v4u vGlobalID, vcc, baseGlobalId, localSizeIdx
v_lshlrev_b32 v4u vGlobalOffset, 2, vGlobalID
Since variables auto-free at last use, the allocator can recycle within the same instruction. Example: the register backing localSizeIdx can be reused for vGlobalID on the same line if lifetimes allow.
Using a Variable
Use variable names instead of raw registers. The assembler looks up the binding and substitutes the concrete s/v register(s):
v_add_i32 v3, v4, myInt; → v_add_i32 v3, v4, v7.
Variable Indexing
For multi-register variables, access specific lanes with [index]. Example: adding two 64-bit values:
... // assign values
v_add_i32 myInt1[0], vcc, myInt1[0], myInt2[0] // low 32
v_add_i32 myInt1[1], vcc, myInt1[1], myInt2[1] // high 32
Free a Variable
Prefer automatic freeing for cleaner code and better register pressure.
Automatic:
A variable is freed at its last use. Lifetimes are tracked, and same-instruction recycling is possible.
Manual:
Use free name1, name2 to extend or end lifetimes explicitly.
...
v_add_u32 myVar1, myVar1, myVar2 // myVar2 last used → auto-freed here
...
free myVar1 // explicitly free later
Manual freeing helps when:
Using GPR indexing (v_movrels / v_movreld), which does not reference the register directly and would otherwise look unused.
You jump back to earlier code that expects a variable still live. Manually delaying free preserves the binding.
Flexible Constants
Instructions that support inline literals accept many forms: decimal, hex, octal, binary, scientific, and labels (distance in bytes).
Examples:
s_add_i32 s3, s4, -12
s_min_u32 s5, s6, 0xabcd
s_min_u32 s5, s6, 10e2
s_min_u32 s5, s6, -10e2
s_mov_b32 s4, 2.
s_mov_b32 s4, -20.0
s_mov_b32 s4, .5
s_mov_b32 s4, -.5
s_mov_b32 s4, 343.432
s_mov_b32 s4, 3.4e4
s_mov_b32 s4, -34.4e-4
s_mov_b32 s4, 0o7654
s_mov_b32 s4, 0b0011111111
#define Support
C-style #define is supported via textual substitution. Use distinctive names (often braced with underscores) to avoid accidental matches. Macro parameters are supported.
#define _hw1_(opt0) Hello opt0 World!
#define _hw2_(opt0,opt1) Hello opt0 World from opt1!
#s_pool and #v_pool
Constrain the allocator to specific registers with #S_POOL and #V_POOL. Place near the top for clarity.
#V_POOL v11, v12, v13, v14, v15, v17, v19, v20, v21, v23, v24, v25
Multiple Statements per Line and Semicolons
Most instructions and commands support multiple statements per line, separated by ;. #v_pool, #s_pool, and #define must be on their own lines.
v_add_i32 v0, v1, v2 // ok
v_add_i32 v0, v1, v2; // ok
v_add_i32 v0, v1, v2; #define _myDef_ 12345678 // not ok
Asm4GCN Project Files
Approximate line counts in parentheses:
GcnISA.cs (1756) — ISA data: instruction tables, register aliases, enums.
Encoder.cs (1404) — Static GcnParcer class; one method per encoding format; converts a statement to opcode bits.
GcnBlock.cs (679) — GcnBlock class; converts a block to byte[].
DataStructs.cs (50) — GcnStmt, Define, AsmVar, etc.
Labels.cs (109) — Label tracking and jump distances.
ParseOperand.cs (346) — Parses operands and validates datatypes; hex/octal/bin to constants.
Program.cs (208) — Command-line entry; library use preferred.
RegPool.cs (356) — Register allocator and pools.
RegUsage.cs (111) — Usage counters and maximums; helps estimate inline needs.
Log.cs (122) — Logging to StringBuilder or console.
Tools.cs (76) — Small helpers like IsBetween().
TestInput.txt (166) — Examples and tests.
Variables.cs (409) — Variable handling; owns RegPool and RegUsage.
Point of Interest
Inline Assembly
A possible approach:
1. Locate and extract inline Asm4GCN blocks.
2. Assemble them in "usage only" mode to get byte size and s/v register counts at max-usage points.
3. Replace inline text in the OpenCL kernel with generated dummy OpenCL that matches byte size, register usage, and params, fenced with barriers to prevent reordering.
4. Compile the dummy kernel; record which registers the driver used.
5. Re-assemble the inline block, now constraining allocation via #S_POOL and #V_POOL to those registers.
6. Find and patch the dummy binary in the program binary with the final assembly.
Status: (3) partially works (FillerKernelAttempts.cl: DummyFillerCode()), but sizing and counts are imperfect. (6) not finished; the dynamic dummy's starting bytes were hard to locate reliably.
Smart Register Packing/Reservations
Naive "first free" allocation wastes space. Think of lifetimes as rectangles: width is register width (1,2,4,8,… regs), height is lifetime in instructions. The goal is to place rectangles to minimize total width (peak registers), respecting alignment (2-wide on even starts; 4-wide on multiples of 4).
Inst 1 A A
Inst 2 A A B C C C C
Inst 3 A A B C C C C D D
Inst 4 B C C C C D D
Inst 5 B D D
Inst 6 E B F F
Inst 7 E F F
Inst 8 E G G F F
Differences from classic rectangle/bin packing: lifetimes are mostly fixed vertically; widths are powers of two; and alignment constraints apply. A simple greedy heuristic works well in practice: place each block into the smallest gap it fits (perfect fits preferred), scored by wasted space. Asm4GCN uses this style of heuristic rather than pure "first fit."
OpenCLwithGCN Sub-Project
OpenCLwithGCN makes Asm4GCN usable from C#. It replaces Asm4GCN kernels with dummy OpenCL kernels, assembles, then patches the dummy binary with the Asm4GCN binary. OpenCL __kernel and Asm4GCN __asm4GCN kernels can coexist in one cl::program.

Features of OpenCLwithGCN
Built-in Text Template Engine
Assembly benefits from programmable text (e.g., unrolling). A simple C#-based template engine runs before assembly. Use [[ ... ]] blocks; print values with [[=expr]]. More details: CodeProject Template Engine Article
Example
v_mov_b32 v[[=i]], v[[=i+4]]
[[}]]
Expands to:
v_mov_b32 v4, v8
v_mov_b32 v5, v9
Mixed OpenCL and Asm4GCN kernels in one cl::program
Use both __kernel and __asm4GCN in the same program. Streams let you compose them. Note: early versions supported only a single __asm4GCN; see Limitations section.
Using OpenCLwithGCN
From Example1.cs:
Compose the source:
__asm4GCN myAsmFunc ( float*, float* )
{
#define _32Float_ 0 offen format:[BUF_DATA_FORMAT_32,BUF_NUM_FORMAT_FLOAT]
s_buffer_load_dword s0, s[4:7], 0x04
s_buffer_load_dword s1, s[4:7], 0x18
s_waitcnt lgkmcnt(0)
s_min_u32 s0, s0, 0x0000ffff
s_buffer_load_dword s4, s[8:11], 0x00
v_mov_b32 v1, s0
v_mul_i32_i24 v1, s12, v1
v_add_i32 v0, vcc, v0, v1
v_add_i32 v0, vcc, s1, v0
v_lshlrev_b32 v0, 2, v0
s_load_dwordx4 s[12:15], s[2:3], 0x60
s_waitcnt lgkmcnt(0)
v_add_i32 v1, vcc, s4, v0
tbuffer_load_format_x v1, v1, s[12:15], _32Float_
s_buffer_load_dword s0, s[8:11], 0x04
s_load_dwordx4 s[4:7], s[2:3], 0x68
s_waitcnt lgkmcnt(0)
v_add_i32 v0, vcc, s0, v0
s_waitcnt vmcnt(0)
v_add_f32 v1, v1, v1
tbuffer_store_format_x v1, v0, s[4:7], _32Float_
s_endpgm
};
__kernel void myOpenClFunc ( __global float* cl_input, __global float* cl_output )
{
size_t i = get_global_id(0);
cl_output[i] = cl_input[i] + cl_input[i];
}; ";
Compile and keep the default environment:
OpenClEnvironment env = gprog.env;
bool success = gprog.GcnCompile(source, out log);
Create the kernel:
Allocate buffers and fill data:
Mem cl_output = env.context.CreateBuffer(MemoryFlags.WriteOnly, dataSz);
// random data
var random = new Random();
const int count = 1024 * 1024;
const int dataSz = count * sizeof(float);
float[] data = (from i in Enumerable.Range(0, count)
select (float)random.NextDouble()).ToArray();
env.cmdQueue.EnqueueWriteBuffer(cl_input, true, 0, dataSz, data);
Set args and enqueue:
kernel.Arguments[1].SetValue(cl_output);
env.cmdQueue.EnqeueNDRangeKernel(kernel, count, 256);
env.cmdQueue.Finish();
float[] results = new float[count];
env.cmdQueue.EnqueueReadBufferAndWait(cl_output, results, dataSz);
OpenCLwithGCN Project Files
OpenClEnvironment.cs (97) — OpenCL environment classes.
OpenClWithGCN.cs (615) — Core logic.
TextTemplate.cs (105) — Single static Expand() for template transformation.
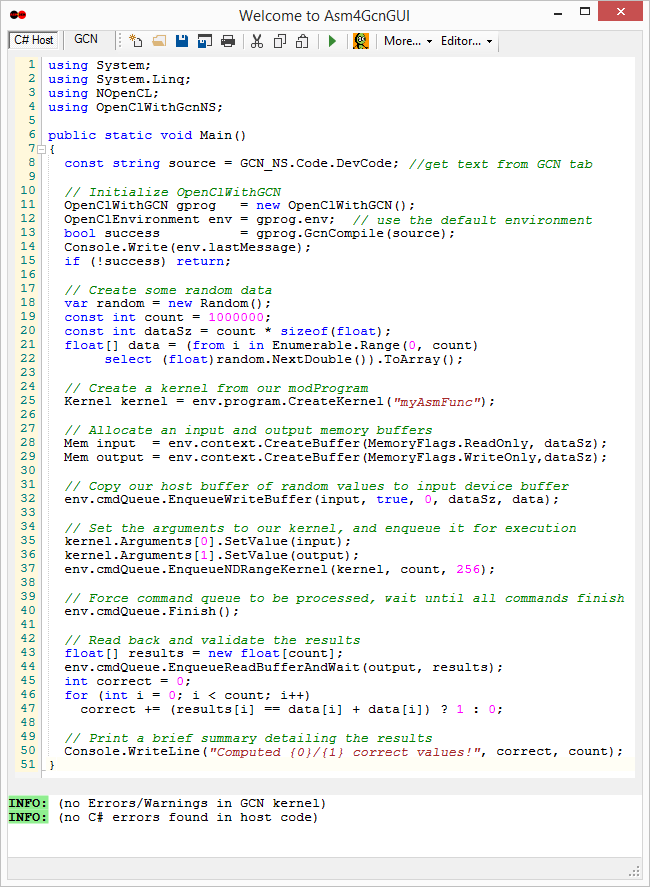
Asm4GcnGUI Windows Interface Sub-Project

A small GUI with syntax highlighting, code completion, and an output panel. Useful for quick kernel tests and teaching. The three panes are: C# host code, GCN assembly code, and compiler output.
The GUI keeps GCN assembly in a separate tab for highlighting. Internally, that text is emitted into a .cs file as:
static class Code {
public const string DevCode = "...";
}
}
The output panel shows assembler messages first, then any C# compile errors. Program output goes to a console window.
Features of the GUI Interface
Directly runnable in Visual Studio — Saves files in a VS-friendly layout. Add references and build.
Syntax highlighting — Using Pavel Torgashov's FastColoredTextBox; helps readability and catches typos.
Code completion — Assembly autocompletion for faster authoring.
Separate host and device panes — Clean separation for language-specific highlighting and organization.
General Topics on GPU Assembly
This section covers GPU assembly broadly.
The Good & the Bad of Programming in GPU Assembly
Advantages
Potentially faster and smaller kernels in expert hands; 2–4× speedups are plausible for hot spots.
Access to instructions/options and special registers unavailable at higher levels.
Understanding ISA details improves OpenCL/CUDA coding.
Humans can sometimes pack data/control more cleverly than a compiler.
Disadvantages
Slower to write than OpenCL/CUDA.
Harder to maintain and read at scale.
Tied to GPU generations; driver updates can break binaries depending on how they're loaded.
OpenCL kernels are portable; assembly is GCN-specific.
More bug-prone; compilers avoid common pitfalls.
Beating a modern compiler on complex kernels is not guaranteed.
Rule of thumb: keep assembly small and surgical. 1–50 lines for critical paths is manageable; compilers regain advantage as complexity grows.
Preload Register Values
Some registers are preloaded when a GCN kernel is launched. These may be driver-dependent.
| Reg | Name |
|---|---|
| s[2:3] | UAV Table Pointer |
| s[2:3]+0x60 | base_resource_const1 (#T) |
| s[2:3]+0x68 | base_resource_const2 (#T) |
| s[4:7] | Imm Const Buffer 0 |
| s[4:7]+0x00 | Grid Size |
| s[4:7]+0x04 | Local Size |
| s[4:7]+0x18 | Base Global ID |
| s[8:11] | Imm Const Buffer 1 |
| s[8:11]+0x00 | param1 offset |
| s[8:11]+0x04 | param2 offset |
| s[8:11]+0x08 | param3 offset |
| s12 | Group ID |
| v0 | Local ID |
GCN Assembly Code Writing Tips
Plan ahead. Prototype in a higher-level language first to validate logic and shape the assembly.
Know the ISA. Study AMD's GCN ISA manual for helpful instructions and options.
Unroll to reduce branches. Fewer jumps often means fewer stalls.
Fit in I-cache. Keep kernels within the CU's shared instruction cache (~32 KB, ≈4–8k instructions).
Minimize registers. More live registers reduce occupancy. Move computations earlier or later to shorten lifetimes.
Practice. Explore, iterate, and read community posts and articles.
Register optimization example:
Original lifetimes: A,B created at 10, first used at 20 (C=A+B), C used at 30
Usage = (2 vars * (20-10)) + (1 var * (30-20)) = 30
Move C=A+B to 11 → (2*(11-10)) + (1*(30-11)) = 21 → one fewer live register from 11–20.
Limitations
No support for 3rd-gen "Volcanic Islands" GPUs (Radeon R9 280, Fury, Nano).
Sensitive to some driver versions (see System Requirements below).
Only AMD GCN 1.0/1.1 GPUs.
Future Wish List
Allow reuse of the same variable name safely.
Support GCN generation 3.
More OpenCL 2.0 support.
Broader driver compatibility.
Inline assembly via robust dummy kernel generation.
Friendlier infix syntax, e.g., varA = varB * varC mapped to the right opcode via types.
Type-aware warnings (I/U/F/B) for mismatched ops.
Videos
Tutorial video(s) are available; some parts may be out of date.
YouTube search for Asm4GCN videosSystem Requirements
AMD GPU with GCN 1.0 or 1.1. 3rd-gen (Volcanic Islands: Radeon R9 280, Fury, Nano) not supported.
Supported AMD drivers: 13.251, 14.501, 15.200, 15.201, 15.300, 16.150. Others may not work.
History
Other GCN Assemblers
cmingcnasm — Minimal GCN assembler in C for GCC/Linux by Sylvain Bertrand. Links: GitHub, GoogleCode
HetPas Assembler (Windows) — By Realhet. Full, feature-rich Windows assembler with Pascal-like host code. Requires disabling Data Execution Prevention; see instructions on the site. Updated frequently; now includes variables. Website
A Special Thanks To
AMD for publishing GCN ISA manuals.
Daniel Bali for an excellent open-source GCN assembler that informed this work.
Derek Gerstmann for a clear OpenCL example; adapted to C# with NOpenCL as the GUI default.
Pavel Torgashov for FastColoredTextBox and Autocomplete menu.
Realhet for HetPas and many insightful posts on the AMD forums and WordPress.
Tunnel Vision Laboratories for the NOpenCL wrapper by Sam Harwell.